Contributions to Analysis of Neural Spike Train Data
My papers on spike train analysis can be put in 5 categories, listed
immediately below.
The context and content of these papers are explained in subsequent sections:
-
Background: Spike Trains as Point Processes
-
-
Spike Counts and Trial-Averaged Firing Rate
-
-
Within-Trial Analysis
-
-
Multiple Neurons
-
-
Decoding and Brain-Machine Interface
The problems attacked
have also been treated by other authors,
but here I omit
references to that other work. Analysis of local field potentials (LFPs) became a substantial component of our research; publications based on LFPs (or both spike trains and LFPs) are intermingled. This page was updated June 2024.
A 2018 overview of computational neuroscience may be found
in this review article and a 2023 review of methods for identifying cross-population interactions may be found here.
- Single Neurons: Spike Counts and Trial-Averaged Firing Rate
- Olson, C.R., Gettner, S.N., Ventura, V., Carta, R., and Kass, R.E.
(2000) Neuronal Activity in Macaque Supplementary Eye Field During
Planning of Saccades in Response to Pattern and Spatial Cues,
Journal of Neurophysiology, 84: 1369-1384.
- DiMatteo, I., Genovese, C.R. and Kass, R.E. (2001) Bayesian
curve fitting with free-knot Splines, Biometrika, 88: 1055-1073.
- Ventura V., Carta R., Kass R.E., Gettner S.N., and Olson, C.R. (2002)
Statistical analysis of temporal evolution in single-neuron
firing rates.
Biostatistics, 3: 1-20
- Kaufman, C., Ventura, V., and Kass, (2005) Spline-based
nonparametric regression for periodic functions and its application
to directional tuning of neurons, Statistics in Medicine, 24: 2255-2265.
- Behseta, S., Kass, R.E., and Wallstrom, G. (2005) Hierarchical
models for assessing variability among functions, Biometrika, 2: 419-434.
- Behseta, S. and Kass, R.E. (2005) Testing equality of two
functions using BARS, Statistics in Medicine, 24:3523-34.
- Behseta, S., Kass, R.E., Moorman, D. and Olson, C. (2007)
Testing equality of several functions:
analysis of single-unit firing rate curves across multiple
experimental conditions,
Statistics in Medicine, 26: 3958-3975.
- Wallstrom, G., Liebner, J., and Kass, R.E. (2008) An implementation of
Bayesian adaptive regression splines (BARS) in C with S and R
wrappers, Journal of Statistical Software, 26: 1-21.
-
Suway, S.B., Orellana, J. McMorland, A.J.C., Fraser, G.W., Liu, Z., Velliste, M., Chase, S.M., Kass, R.E., and Schwartz, A.B. (2017)
Temporally segmented directionality in the motor cortex, Cerebral Cortex, 7: 1-14.
- Single Neurons: Within-Trial Analysis
- Kass, R.E. and Ventura, V. (2001)
A spike train probability model, Neural Computation, 13: 1713-1720.
- Brown, E.N., Barbieri, R., Ventura, V., Kass, R.E., and Frank,
L.M. (2002) The time-rescaling theorem and its application to neural
spike train data analysis. Neural Computation, 14: 325-346.
- Vu, V.Q., Yu, B., and Kass, R.E. (2007)
Coverage adjusted entropy estimation,
Statistics in Medicine, 26: 4039-4060.
- Koyama, S. and Kass, R.E. (2008) Spike train probability models for
stimulus-driven leaky integrate-and-fire neurons, Neural Computation,
20: 1776-1795.
- Vu, V.Q., Yu, B. and Kass, R.E. (2009a) Information in the
non-stationary case, Neural Computation, 21: 688-703.
- Tokdar, S., Xi, P., Kelly, R.C., and Kass, R.E. (2009) Detection
of bursts in extracellular spike trains using hidden semi-Markov
point process models, Journal of Computational Neuroscience,
29: 203-212.
- Koyama, S., Omi, T., Kass, R.E., and Shinomoto, S. (2013) Information transmission using non-Poisson regular firing Neural Computation , 25: 854-876.
- Perez, O., Kass, R.E., and Merchant, H. (2013) Trial time warping to discriminate stimulus-related from movement-related neural activity Journal of Neuroscience Methods 212: 203-210.
- Wang, W., Tripathy, S.J., Padmanabhan, K., Urban, N.N., and Kass, R.E. (2015) An empirical model for reliable spiking activity , Neural Computation, August 2015, 27: 8, 1609--1623.
-
Arai, K. and Kass, R.E. (2017)
Inferring oscillatory modulation in neural spike trains , PLoS Computational Biology, 13: e1005596.
-
Chen, Y., Xin, Q., Ventura, V., and Kass, R.E. (2019) Stability of point process spiking neuron models , Journal of Computational Neuroscience, 46: 19-32.
-
Glasgow, N.G., Chen, Y., Korngreen, A., Kass, R.E., and Urban, N.N. (2023)
A biophysical and statistical modeling paradigm for connecting neural physiology and function. Journal of Computational Neuroscience, 51: 263-282.
- Multiple Neurons and Local Field Potentials
- Ventura, V. Cai, C., and Kass, R.E. (2005a) Trial-to-trial variability
and its effect on time-varying dependence between two neurons,
Journal of Neurophysiology, 94: 2928-2939.
- Ventura, V., Cai, C., and Kass, R.E. (2005b) Statistical assessment
of time-varying dependence between two neurons,
Journal of
Neurophysiology, 94: 2940-2947.
- Kass, R.E. and Ventura, V. (2006) Spike count correlation increases
with length of time interval in the presence of trial-to-trial
variation, Neural Computation, 18:2583-2591.
- Behseta, S., Berdyyeva, T., Olson, C.R., and Kass, R.E. (2009)
Bayesian correction for attenuation of correlation
in multi-trial spike count data, Journal of Neurophysiology,
101: 2186-2193.
- Kelly, R.C., Smith, M.A., Kass,R.E., and Lee, T.-S. (2010a)
Local field potentials indicate network state and account for
neuronal response variability, Journal of Computational
Neuroscience, 29: 567-579.
- Kelly, R.C, Smith, M.A., Kass, R.E., and Lee, T.-S. (2010b)
Accounting for network effects in neuronal responses using L1
penalized point process models, Advances in Neural Information
Processing Systems, 23.
- Kass, R.E., Kelly, R.C., and Loh, W.-L. (2011) Assessment of synchrony
in multiple neural spike trains using loglinear point process models,
Annals of Applied Statistics, 5: 1262--1292.
- Kelly, R.C. and Kass, R.E. (2012)
A framework for evaluating pairwise and multiway synchrony among stimulus-driven neurons, Neural Computation 24: 2007-2032.
- Scott, J.G., Kelly, R.C., Smith, M.A., Zhou, P. and Kass, R.E. (2015) False discovery rate regression: an application to neural synchrony detection in primary visual cortex , Journal of the American Statistical Association, 110: 459-471.
- Zhou, P., Burton, S.D., Snyder, A.C., Smith, M.A., Urban, N.N., and Kass, R.E. (2015) Establishing a statistical link between network oscillations and neural synchrony, PLoS Computational Biology, 11:e1004549.
- Vinci, G., Ventura, V., Smith, M.A., and Kass, R.E. (2016)
Separating spike count correlation from firing rate correlation , Neural Computation, 28: 849-881.
-
Vinci, G., Ventura, V., Smith, M.A., and Kass, R.E. (2018a) Adjusted regularization of cortical covariance , Journal of Computational Neuroscience, 45: 83-101.
-
Vinci, G., Ventura, V., Smith, M.A., and Kass, R.E. (2018b)
Adjusted regularization in latent graphical models: Application to multiple-neuron spike count data , Annals of Applied Statistics, 12: 1068-1095. Pre-publication draft and supplementary material.
-
Klein, N., Orellana, J., Brincat, S., Miller, E.K., and Kass, R.E. (2020) Torus graphs for multivariate phase coupling analysis, Annals of Applied Statistics, 14: 635-660,
and supplementary material. Tutorial and code here.
-
Bong, H., Liu, Z., Ren, Z., Smith, M.A., Ventura, V. and Kass, R.E. (2021)
Latent Dynamic Factor Analysis of High-Dimensional Neural Recordings, 34th Conference on Neural Information Processing Systems (NeurlPS),
Vancouver, Canada.
-
Klein, N., Siegle, J.H., Teichert, T. and Kass, R.E. (2021). Cross-population coupling of neural activity based on Gaussian process current source densities. PLoS Computational Biology, 17: e1009601.
-
Chen, Y.. Douglas, H., Medina. B.J., Olarinre, M., Siegle, J.H., and Kass, R.E. (2022) Population burst propagation across interacting areas of the brain, Journal of Neurophysiology, 128: 1578-1592.
-
Urban, K., Bong, H., Orellana, J., and Kass, R.E. (2023) Oscillating neural circuits: Phase, amplitude, and the complex normal distribution, Canadian Journal of Statistics, 51: 824-851.
- Decoding and Brain-Machine Interface
- Brockwell, A.E., Rojas, A. and Kass, R.E. (2004) Recursive
Bayesian decoding of motor cortical signals by particle filtering,
Journal of Neurophysiology, 91: 1899-1907.
- Jarosiewicz, B., Chase, S.M., Fraser, G.W., Velliste, M. Kass, R.E.,
and Schwartz, A.B.(2008) Functional network reorganization during
learning in a brain-machine interface paradigm.
Proceedings of the National Academy of Sciences,105:19486-19491.
- Chase, S.M., Schwartz, A.B., and Kass, R.E. (2009) Bias, optimal linear
estimation, and the differences between open-loop simulation and
closed-loop performance of spiking-based brain computer interface
algorithms, Neural Networks, 22: 1203-1213.
- Koyama, S., Chase, S.M., Whitford, A.S., Velliste, M., Schwartz,
A.B., and Kass, R.E. (2009) Comparison of brain-computer
interface decoding algorithms in open-loop and closed-loop control,
Journal Computational Neuroscience, 29: 73-87.
- Koyama, S., Castellanos Pérez-Bolde, L., Shalizi, C.R., and
Kass, R.E. (2010) Approximate methods for state-space models,
Journal of the American Statistical Association, 105: 170-180.
- Chase, S.M., Schwartz, A.B., and Kass, R.E. (2010) Latent inputs
improve estimates of neural encoding in motor cortex, Journal of
Neuroscience, 30: 13873-13882.
- Chase, S., Kass, R.E., and Schwartz, A.B. (2012)
Behavioral and neural correlates of visuomotor
adaptation observed through a brain-computer interface in primary motor cortex, Journal of Neurophysiology, 108:624-644.
- Zhang, Y., Schwartz, A.B., Chase, S.M., and Kass, R.E. (2012)
Bayesian learning in assisted brain-computer interface tasks,
IEEE Engineering in Medicine and Biology, 2012 Annual International Conference of the IEEE (EMBC), 2740-2743.
-
Orellana, J., Rodu, J., and Kass, R.E. (2017)
Population vectors can provide near optimal integration of information, Neural Computation, 29: 2021-2029.
- Reviews, Reflections, and Edited Volumes
- Kass, R.E., Ventura, V. and Cai, C. (2003)
Statistical smoothing of neuronal data, NETWORK: Computation in Neural
Systems, 14:5-15.
- Brown, E.N., Kass, R.E., and Mitra, P.P. (2004) Multiple neural spike
trains analysis: state-of-the-art and future challenges,
Nature Neuroscience, 7: 456-461.
- Kass, R.E., Ventura, V., and Brown, E.N. (2005) Statistical
issues in the analysis of neuronal data, Journal of Neurophysiology,
94: 8-25.
- Brockwell, A.E., Kass, R.E., and Schwartz, A.B. (2007)
Statistical signal processing and the
motor cortex, Proceedings of the IEEE,
95: 881-898.
- Brown, E.N. and Kass, R.E. (2007) Special Issue on ``Statistical
Analysis of Neuronal Data'' (preface), Statistics in Medicine,
26: 3827-3829.
- Kass, R.E. (2008) Adaptive Spline Smoothing of Neural Data. In
Neural Signal Processing: Quantitative Analysis of Neural
Activity, (Mitra, P., ed.) Washington DC: Society for
Neuroscience, pp. 35-42.
- Paninski, L., Brown, E.N., Iyengar, S., and Kass, R.E. (2008)
Statistical models of spike trains. In Stochastic Methods in
Neuroscience, (Liang, C. and Lord, G.J., eds.) Oxford, Clarendon
Press, 278-303.
- Koyama, S., Eden, U., Brown, E.N. and Kass, R.E. (2009)
Bayesian decoding of neural spike trains, Annals of the Institute of Statistical Mathematics, 62: 37-59.
- Brown, E.N. and Kass, R.E. (2009) What is Statistics? (with discussion)
American Statistician, 63: 105-123.
- Kass, R.E. (2010a) Guest Editorial: Analysis of
Neural Data, Journal of Computational Neuroscience, 29: 1-2.
- Kass, R.E. (2010b) How should indirect evidence be used? Invited
comment on ``Indirect Evidence,'' by Bradley Efron, Statistical
Science, 25: 166-169.
- Kass, R.E. (2011) Statistical inference: the big picture (with
discussion), Statistical Science, 26: 1-9.
-
Harrison, M.T., Amarasingham, A., and Kass, R.E. (2013) Statistical identification of synchronous
spiking. In,
Spike Timing: Mechanisms and Function, Eds: Patricia Di Lorenzo
and Jonathan Victor. Taylor & Francis, pp. 77-120.
-
Kass, R.E. (2014) Spike train , in Encyclopedia of Computational Neuroscience, edited by D. Jaeger and R. Jung, Springer.
- Kass, R.E. (2015) The gap between statistics education and statistical practice. (Comment on "Mere renovaton is too little too late: we need to re-think our undergraduate curriculum from the ground up" by George Cobb), The American Statistician, 69. Online Discussion: Special Issue on Statistics and the Undergraduate Curriculum..
- Kass, R.E., Caffo, B., Davidian, M., Meng, X.-L., Yu, B., and Reid, N. (2016)
Ten simple rules for effective statistical practice, PLoS Computational Biology, 12:e1004961.
-
Kass, R.E., Amari, S.-I., Arai, K., Brown, E.N., Diekman, C.O., Diesmann, M., Doiron, B., Eden, U.T., Fairhall, A.L., Fiddyment, G.M., Fukai, T., Grün, S., Harrison, M.T., Helias, M., Nakahara, H., Teramae, J.-N., Thomas, P.J., Reimers, M., Rodu, J., Rotstein, H.G., Shea-Brown, E., Shimazaki, H., Shinomoto, S., Yu, B.M., and Kramer, M.A. (2018)
Computational neuroscience: Mathematical and statistical perspecitives , Annual Review of Statistics and its Application, 5: 183-214. Pre-publication draft available here.
-
Kass, R.E. and Matheo, L.M. (2019) Letter to the Editor concerning "Brain change in addiction as learning, not disease," The New England Journal of Medicine, 380: 301.
-
Kass, R. E. (2021) The Two Cultures: Statistics and Machine Learning in Science, Observational Studies, 7: 135--144.
-
Kass, R.E., Bong, H., Olarinre, T., Xin, Q., and Urban, K. (2023) Identification of interacting neural populations: Methods and statistical considerations, Journal of Neurophysiology, 130:475-496.
NOTE: LFPs, which are low-pass filtered (smoothed) versions of the raw voltage recordings, are generally considered to represent the summed voltage contributions generated at synapses in the neighborhood of the electrode. There are disagreements about the spatial extent of this "neighborhood," see references in our 2023 review (linked above near the beginnng of this page). Spike trains instead result from high-pass filtering of the voltage recordings, followed by a process of assigning apparent action potentials to particular neurons (as more than one neural source is picked up by the electrode), which is known as "spike sorting."
One of the most important techniques in learning about the functioning
of healthy and diseased brains has involved examining neural activity
in laboratory animals under varying experimental conditions. Neural
information is represented and communicated through series of action
potentials, or spike trains (Kass, 2014).
Numerous investigations
have documented the way neural firing rate increases in
response to a sensory stimulus, or preceding an action.
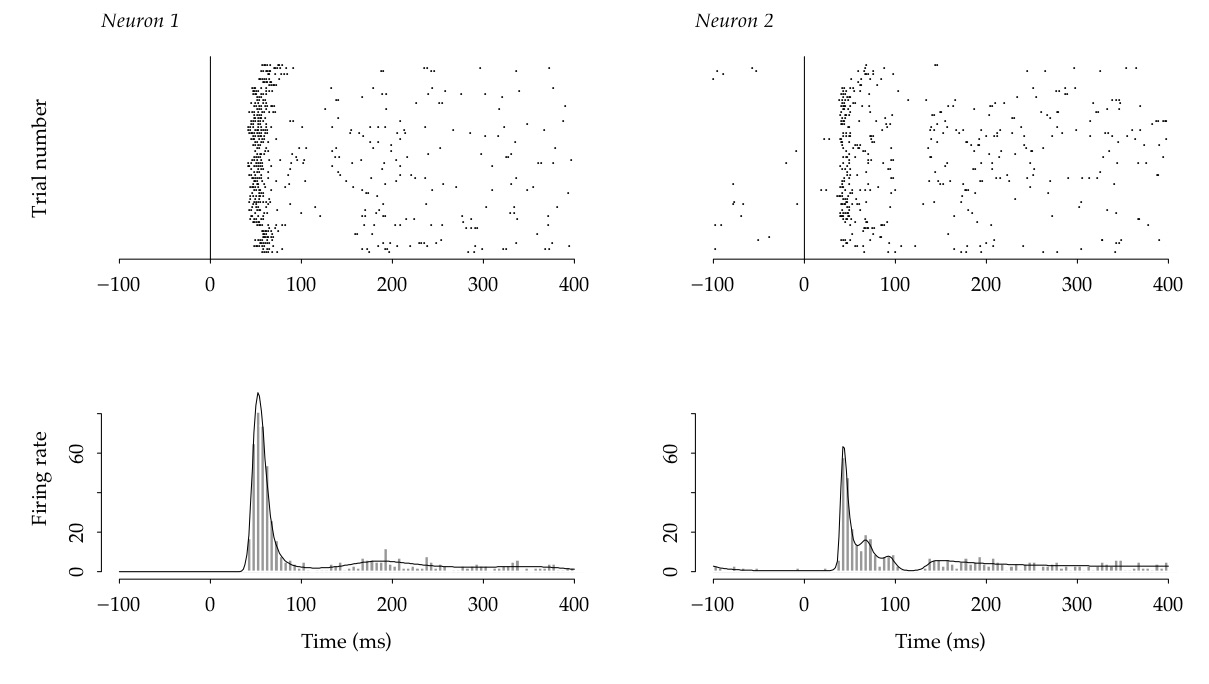
Figure 1:
Raster plots (top) and Peri-Stimulus Time Histograms (PSTHs, bottom)
from two neurons recorded simultaneously in primary visual cortex.
Each line of a raster plot displays spike times, as dots, for one
experimental trial.
Spike times in each raster plot are aggregrated into 5 millisecond
bins, then counted and displayed in the corresponding PSTH, in units
of spikes per second.
The solid curves are the smoothed estimates of
trial-averaged firing rate , and were
obtained using BARS (which will be explained below).
|
|
The top two panels of
Figure 1 display spike trains
recorded simultaneously from two neurons in primary visual
cortex during 64 replications, or trials,
of a single experimental condition.
In each of the lower panels of Figure 1 the data
have been aggregated across trials into bins
of width delta t = 5,
and normalized to units of spikes per second,
yielding a Peri-Stimulus Time
Histogram (PSTH). This pair of PSTH plots shows a clear change in firing rate across the several hundred milliseconds following time zero, which refers to the onset of a visual stimulus.
Based on a large sample of data, the firing rate (FR) across a substantial interval of time could be defined as FR=(number of spikes)/(interval of time). However, it is desirable to avoid dependence on a specific time interval; furthermore, as may be seen in Figure 1,
spikes occur irregularly both within and across repeated trials.
It is therefore reasonable to think of a spike train as
a stochastic sequence of isolated points in time, i.e., as a point process, and to introduce a theoretical, instantaneous firing rate in the form of the point process intensity function.
Analyses of trial-averaged firing rate involve
trial-aggregrated data, where the trial identity of each spike time
is ignored.
In point process terminology, the trial-averaged firing rate
is the marginal intensity function.
The PSTH may be considered an estimate
of the marginal intensity function.
Analyses
of within-trial firing rate, on the other hand,
involve the original spike trains themselves, without
aggregration, and are based on the conditional
intensity function. Letting H_t denote the
history of spike times prior to time t,
the point process probability density function,
and thus the likelihood function, may be written in terms
of the conditional intensity function
lambda(t | H_t), which is also the hazard function
for the waiting time distribution (waiting for the next spike). On
a given experimental trial the conditional intensity determines
the conditional
probability that the next spike will occur at time:
P(spike in (t, t + dt)| H_t)= lambda(t | H_t)dt.
In the Poisson case
the process is memoryless
and the conditional intensity reduces to the history-independent
form lambda(t | H_t) = lambda(t).
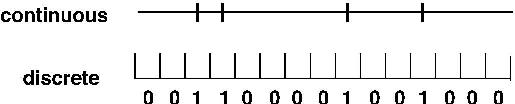
Figure 2:
Spike trains are measured in discrete time
but are conceptualized in continuous time.
In each time bin a 1 indicates a spike has occurred.
The sequence of 1s and 0s then form a binary time series.
|
|
Spike times are recorded to fixed accuracy delta t.
An observed spike train is thus a binary time series, as pictured
in Figure 2.
It is not hard to show that the point process likelihood function
approximates the corresponding binary time series likelihood function,
for small delta t.
Typically delta t = 1 millisecond and the approximation is very
good.
Importantly, this means that if a point process model sets
log lambda(t | H_t)
equal to some function of covariates,
the spike train data may then
be analyzed using generalized linear models and familiar variants of
them.
From 1998 to 2010
All of the foregoing was discussed by Brillinger, notably in a 1988
paper in Biological Cybernetics,
but no new insights into neural behavior were offered and
the main ideas did not begin to
penetrate the neurophysiology literature until at least 10 years
later. In 1998 Emery Brown and colleagues
published a paper that introduced state-space
modeling, in the context of point processes, to neuroscience.
That year he and I decided to learn about existing
approaches to spike train data analysis with the goal of writing a
review article.
As Emery and I dug into the literature we discovered gaping holes,
holes so large that we could not write a review until they were
filled. With various colleagues Emery and I, mostly separately,
worked on several problems, as did some other
statistically-oriented researchers in neurophysiology.
Finally, by 2005, together with Valerie Ventura, we were able
to finish and publish
the review article we had set out to write 7 years earlier
(Kass, Ventura, Brown, 2005; see also Brown, Kass, and Mitra, 2004).
Along the way, in 2002, Emery and I began a series of international workshops
Statistical Analysis of
Neural Data (SAND), bringing together experimenters, computational
neuroscientists, and
statisticians. It is impossible to say what impact these
research and outreach efforts
had on the field, but the quality of statistical analysis of spike
train data improved dramatically over this period.
The first SAND meeting devoted considerable time to problem definition.
At the fifth SAND meeting, in 2010, investigators reported
development and application of
state-of-the-art statistical methodology in attacking
well-formulated and important scientific questions.
(See Brown and Kass, 2007; Kass, 2010a.)
Our experiences during this time
prompted reflections on the nature of statistics
and statistical training (Brown and Kass, 2009), and on the
connections between statistical practice and the foundations of statistical
inference (Kass, 2010b, 2011).
Since 2010 Subsequent work has moved more systematically into analysis of simultaneously-recorded multiple spike trains. Challenges often involve regularization and, increasingly, inferences about cross-area coupling (e.g., Vinci et al., 2018b). A major review of computational neuroscience, with an emphasis on the complementarity of mathematical and statistical modeling of spike train data, was given by Kass and 24 others in 2018 in the Annual Reviews series and may be found here. Also, in 2014 Emery and I, together with Uri Eden, published our textbook Analysis of Neural Data.